프로그램은 크게 instruction(명령)과 data로 구분되며, 일반적으로 4가지, 좀더 세분화 하면 5가지 정도 구분 할 수 있다.
--> 아래 그림 참조.
1) code 영역
- 코드 자체를 구성하는 메모리 영역으로 Hex파일이나 BIN파일 메모리다.
- 프로그램 명령이 위치하는 곳으로 기계어로 제어되는 메모리 영역이다.
2) data 영역
- 전역변수(global), 정적변수(static), 배열(array), 구조체(structure) 등이 저장된다.
가) 초기화 된 데이터는 data 영역에 저장되고,
나) 초기화 되지 않은 데이터는 BSS (Block Stated Symbol) 영역에 저장된다.
- 프로그램이 실행 될 때 생성되고 프로그램이 종료 되면 시스템에 반환 된다.
- 함수 내부에 선언된 Static 변수는 프로그램이 실행 될 때 공간만 할당되고, 그 함수가 실행 될 때 초기화 된다.
Q) data영역과 bss 영역을 구분 하는 이유?
컴파일 해서 이미지를 올릴 때 초기화 되지 않은 데이터까지 올리게 되면 ROM 사이즈가 커지기 때문에 구분하지 않았을까? -> 혹시 정확히 아시는 분은 답변 부탁 드립니다.
3) heap 영역
- 필요에 의해 동적으로 메모리를 할당 하고자 할 때 위치하는 메모리 영역으로 동적 데이터 영역이라고 부르며, 메모리 주소 값에 의해서만 참조되고 사용되는 영역이다.
- 이 영역에 데이터를 저장 하기 위해서 C는 malloc(), C++은 new() 함수를 사용한다.
4) stack 영역
- 프로그램이 자동으로 사용하는 임시 메모리 영역이다.
- 지역(local) 변수, 매개변수(parameter), 리턴 값 등 잠시 사용되었다가 사라지는 데이터를 저장하는 영역이다.
- 함수 호출 시 생성되고, 함수가 끝나면 시스템에 반환 된다.
- 스택 사이즈는 각 프로세스마다 할당 되지만 프로세스가 메모리에 로드 될 때 스택 사이즈가 고정되어 있어, 런타임 시에 스택 사이즈를 바꿀 수는 없다.
- 명령 실행시 자동 증가/감소 하기 때문에 보통 메모리의 마지막 번지를 지정 한다.
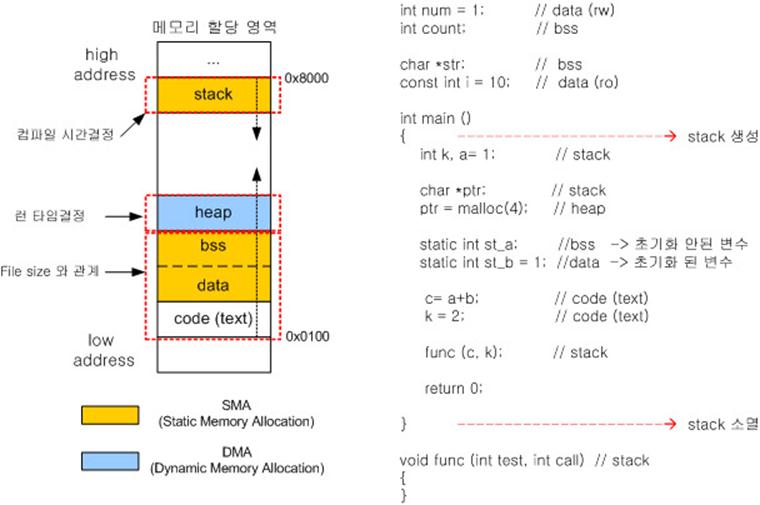
요약)
1) code(text), data, stack 영역은 컴파일러가 알아서 메모리영역을 결정한다. 즉 컴파일 할 때 data영역과 stack영역의 크기를 계산해서 필요한 메모리 공간을 가지고 된다. heap 영역은 개발자에 의해 프로그램 동작시 결정된다.
ex) C언어에서 배열 선언시 incomplete type으로 사용하면 컴파일 할 때 에러가 발생하게 된다.
2) code, data, heap 영역은 하위 메모리부터 할당되고, stack 영역은 상위 메모리부터 할당 된다.
3) SMA (Static Memory Allocation) : 정적 메모리, 메모리의 data 영역, stack 영역을 사용한다.
- Data 영역 : 프로그램 시작과 동시에 할당된 영역이 잡히고 끝나면 OS 에 반환한다.
- Stack 영역 : 함수 시작과 동시에 할당된 영역이 잡히고 끝나면 OS에 반환한다.
4) DMA (Dynamic Memory Allocation) : 동적 메모리, 메모리의 heap 영역을 사용한다.
- Heap 영역 : stack에서 pointer 변수를 할당하고, 그 pointer가 가리키는 heap 영역의 임의의 공간부터 원하는
크기 만큼 할당해 사용한다.
written by 브랜든 (v 1.1)
P.S 부족한 부분이나 잘못된 부분은 댓글 부탁드립니다. (by 브랜든)
출처: https://sfixer.tistory.com/entry/메모리-영역code-data-stack-heap [Block Busting]
'잡동사니' 카테고리의 다른 글
| 8비트 MCU 또는 32비트 MCU 선택 기준 (0) | 2019.10.09 |
|---|---|
| 구조체와 const에 관하여 (0) | 2019.07.18 |
| 정수를 문자열로 변환하기 (0) | 2019.06.27 |
| #ifndef ~ #endif (0) | 2019.06.20 |
| MY PC에서 ROS MASTER를 통해 ethernet 연결된 Device로 접근하는 법 (0) | 2019.05.03 |
